
[Algorithm] BFS DFS
업데이트:
BFS DFS에 대한 설명은 C언어로 쉽게 풀어 쓴 자료구조 책을 참고하였습니다.
1. 그래프의 탐색
그래프의 탐색은 하나의 정점으로부터 시작하여 차례대로 모든 정점을 한 번씩 방문하는 것입니다. 그래프 문제는 가장 기본적이면서 자주 등장하는 문제중 하나인데 어떤 노드로 부터 다른 노드까지 갈 수 있는지 파악하는 문제부터 출발지부터 목적지까지 가는 가장 빠른 경로 등을 찾는 데도 사용됩니다. 그래프에 대한 기초 개념은 “[Algorithm] 그래프 기초”를 참고해주세요.
이 포스팅에서는 그래프 탐색 방법인 너비 우선 탐색(Breath First Search)와 깊이 우선 탐색(Depth First Search)를 살펴보도록 하겠습니다.
먼저 둘의 차이점을 간단하게 보면 너비 우선 탐색은 해당 노드로부터 인접한 모든 노드들을 방문한 뒤 다음 순서로 넘어가는 것이고 깊이 우선 탐색은 시작 정점으로 부터 한 방향으로 계속 가다가 더이상 갈 수 없게되면 다시 가장 가까운 정점으로 돌아와 탐색을 진행하는 방법입니다. 그림을 통해서 살펴보도록 하겠습니다.
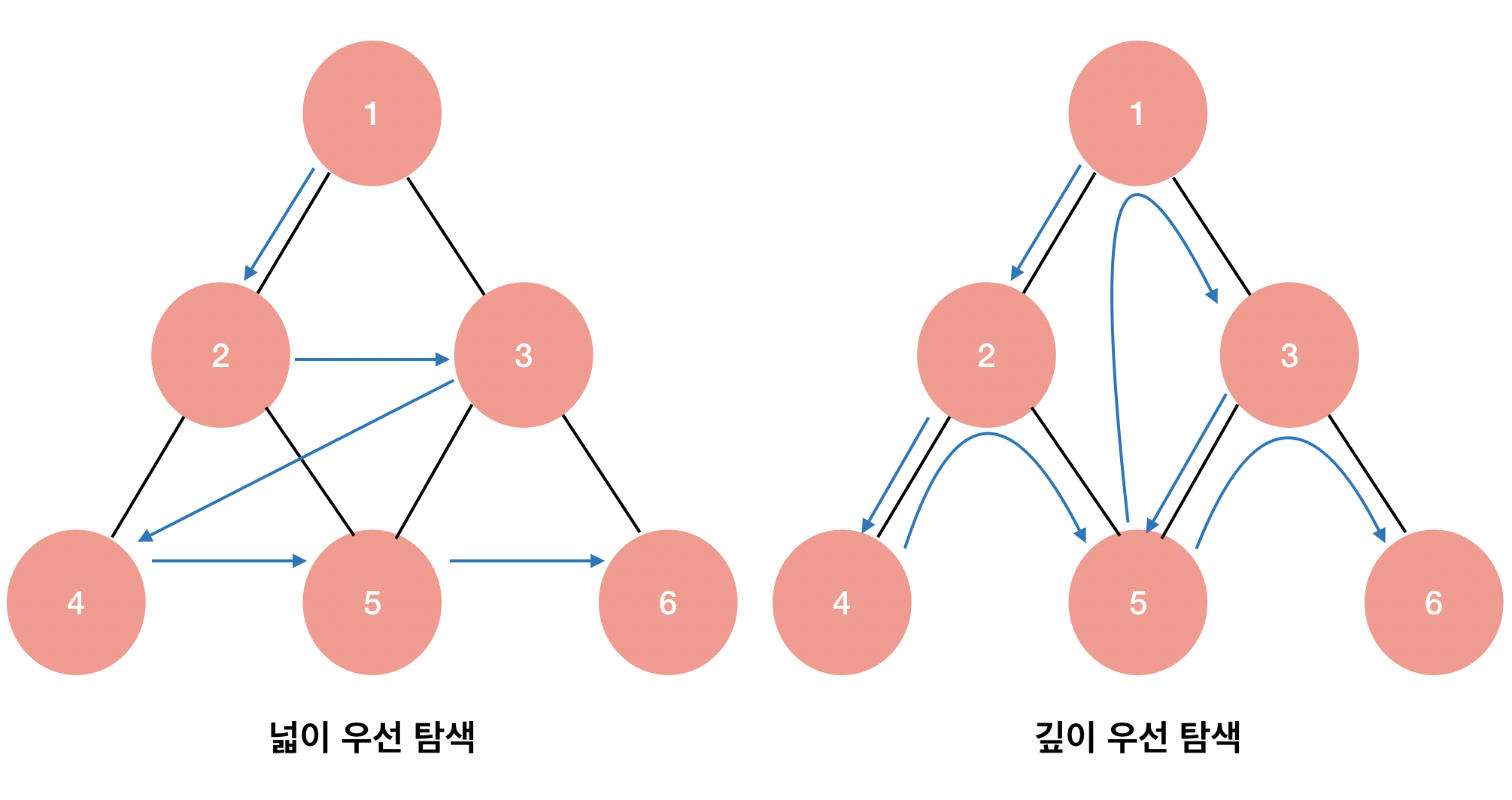
2. 너비 우선 탐색(BFS)
BFS는 시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법입니다. 알고리즘 탐색 방법은 다음과 같습니다.
- 정점을 방문한다
- 정점에 인접한 정점을들 저장해 놓는다
- 저장된 정점 중 가장 먼저 저장된 정점을 꺼내서 방문한 뒤 더 이상 저장된 정점이 없을 때 까지 2~3을 반복한다
여기서 눈치 채신 분이 계실 지 모르겠지만 BFS는 먼저 저장된 데이터를 먼저 꺼내서 쓰는 자료구조인 큐(queue)를 이용해서 구현됩니다. pseudo-code로 작성해 보면 다음과 같습니다.
breath_first_search(v):
v를 방문 했다고 표시
큐 Q에 v를 삽입
while(Q가 empty가 아니면 반복):
Q에서 정점 v를 삭제:
for (v에 인접한 모든 정점 u에 대해서):
if (u가 아직 방문되지 않았으면)
then u를 Q에 삽입;
u를 방문 되었다고 표시;
3. 깊이 우선 탐색(DFS)
DFS는 하나의 정점에서 시작하여 그 정점의 인접한 정점 중 아직 방문하지 않은 정점이 없으면 탐색을 종료하고 있으면 방문하여 그 정점으로부터 다시 DFS를 진행하는 재귀적인 방법으로 되는 탐색 방법입니다. 알고리즘 탐색 방법은 다음과 같습니다.
- 정점을 방문한다
- 1.의 정점으로부터 인접한 정점 중 아직 방문하지 않은 정점이 없다면 탐색을 종료하고 가장 마지막으로 방문했던 정점으로 돌아가서 DFS를 진행한다
- 1.의 정접으로부터 인접한 정점 중 아직 방문하지 않은 정점이 있다면 그 정점을 방문하고 해당 정점으로부터 다시 DFS를 진행한다.
BFS와 다르게 DFS는 인접한 정점이 없거나 모두 방문했을 경우 가장 마지막으로 방문했던 정점으로 돌아가서 탐색을 진행하게 됩니다. 마지막으로 저장된 데이터를 먼저 꺼내 쓰는 자료구조인 스택(stack)을 사용하는 알고리즘 입니다. pseudo-code로 작성해 보면 다음과 같습니다.
depth_first_search(v):
v를 방문하였다고 표시:
for (v에 인접한 모든 정점 u에 대해서):
if (u가 아직 방문되지 않았다면)
then depth_first_search(u)
BFS와 DFS에 관한 문제나 설명을 더 보고싶다면 BFS DFS를 사용한 기본적인 문제인 “[백준] 11724번: 연결 요소의 개수”을 참고하거나 “Tags”에서 BFS, DFS 또는 Brute Force에 해당하는 포스트를 참고해주세요!
댓글남기기