
[Hadoop] 하둡이란?
업데이트:
하둡을 설치해야되는 일이 생겼는데 그 전에 하둡이 뭔지 궁금해져서 이 포스팅을 작성하게 되었습니다.
하둡이 뭘까?
하둡은 빅데이터를 고사양 단일서버가 아닌 저사양의 여러 서버에서 분산처리할 수 있도록 도와주는 프레임워크 입니다.
하둡은 2006년 더그 커팅(Doug Cutting)과 마이크 캐퍼렐라(Mike Cafarella)가 개발하였습니다.
하둡은 빅데이터 시장에 있어서 뺴놓을 수 없는 중요한 역할을 하고 있습니다. 아마존, 마이크로소프트, IBM, 오라클 등 우리가 들어본 많은 대기업들이 하둡을 사용하고 있기 때문인데요 국내에서도 SKT, 네이버, 카카오 등 많은 기업들이 하둡을 사용하여 빅데이터 처리를 하고 있습니다.
하둡이 왜 많이 쓰일까?
하둡이 이렇게 널리 쓰이게 되고 커져가는 빅데이터 시장에서 중요한 역할을 하게 된 것은 2가지 특징 때문입니다.
첫번째 특징은 오픈소스라는 것입니다. 비싼 비용을 들여 유지해야하는 RDMS와 달리 하둡은 무료이기 때문에 빅데이터를 저장하는데 비용적 부담이 줄어들게 됩니다.
하둡이 RDMS와 비교해 비용적 부담이 적은 이유는 두번째 특징과도 관련이 있는데요 바로 하둡은 분산처리 기술입니다. 하둡은 컴퓨터 여러개를 병렬로 연결하여 분산 프로그래밍을 수행할 수 있기 때문에 고사양의 컴퓨터를 필요로 하지 않습니다. 또한 일부 컴퓨터가 고장났을 경우에도 전체 시스템에 주는 영향이 적습니다. 그렇기 때문에 서버를 추가하거나 유지하는 비용이 RDBMS보다 적을 수 밖에 없습니다.
하둡의 4가지 특징
- Economical: 경제적이다
- Reliable: 데이터를 하나의 컴퓨터가 아닌 여러대의 컴퓨터에 저장하기 때문에 시스템 다운 등에 민감하지 않다.
- Scalable: 하둡은 수평적, 수직적 확장이 모두 가능하다. 무슨 뜻이냐면은 성능을 업그레이드 하기 위해 이미 사용되고 있는 컴퓨터의 성능을 업그레이드 할 수도 있고 새로운 컴퓨터를 추가하는 방식으로도 성능을 업그레이드 할 수 있다는 말이다.
- Flexible: 정형, 비정형 데이터를 모두 저장하고 언제든지 사용할 수 있다.
하둡 Ecosystem
하둡은 코어 프로젝트 Hadoop Distributed File System (HDFS), MapReduce와 다양한 하둡 서브 프로젝트들이 모여서 하둡 Ecosystem을 구성하고 있습니다.
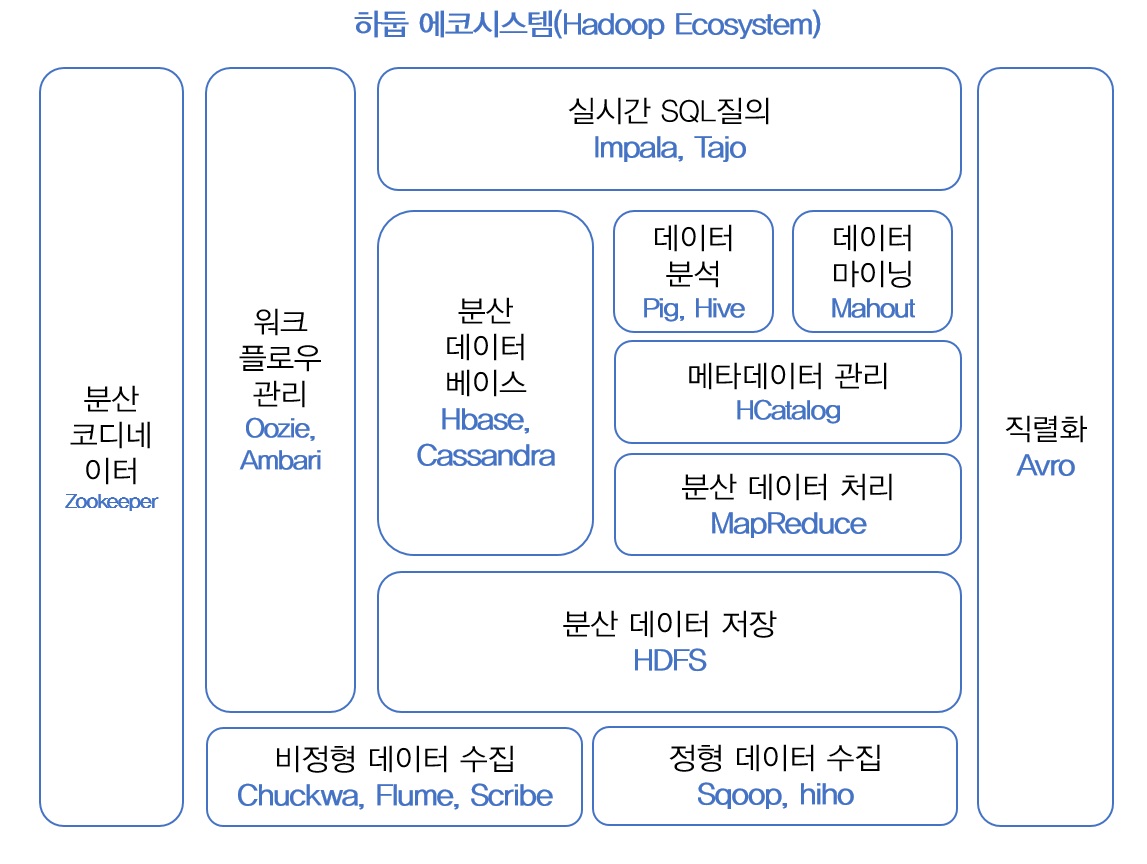
다음 포스팅에는 하둡 Ecosystem을 살펴보도록 하겠습니다.
참고링크
Big Data and Hadoop Ecosystem Tutorial
Enough is not enough 블로그 - [분산알고리즘] Hadoop(하둡) 이란?
댓글남기기