
ResNet
업데이트:
참고 논문 링크: https://arxiv.org/pdf/1512.03385.pdf
ResNet이 뭘까?
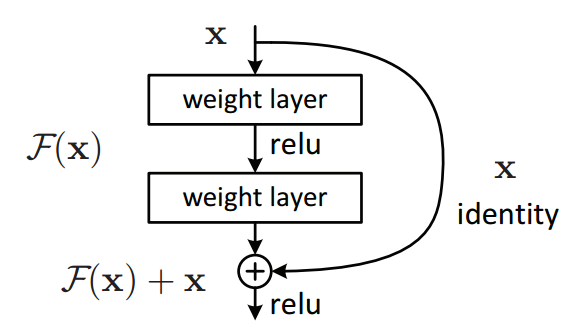
ResNet의 Network를 살펴보면 다음과 같습니다. ResNet은 layer가 깊어질수록 발생하는 gradient vanishing/exploding 현상을 방지하기 위에 원본 데이터를 함수의 output에 더해서 학습시키는 방법을 채택했습니다. 몇개의 layer를 건너뛰어서 원본 데이터를 더해주는 방식을 skip connection이라고 부릅니다.
Residual?
그렇다면 Residual learning이라는 이름이 붙은 이유는 뭘까요? 먼저 Residual을 정의해보도록 하겠습니다. R(x) = Output - Input 이라고 할 수 있습니다. 기존 neural network 의 목표가 input x가 있을 때 H(x)의 distribution을 찾는 것이 목적이었다면 ResNet의 목표는 H(x) = R(x) + x의 distribution을 찾는 것 이 목적이라는 것을 알 수 있습니다. x는 input이고 H(x)는 함수의 output이므로 결국 우리가 찾는 것은 H(x) - x = R(x) 즉, residual이라고 할 수 있습니다.
Bottleneck Architecture
네트워크의 깊이가 깊어지면 연산량이 그에 따라 많아질 수 밖에 없습니다. 이를 해결하기 위해서 ResNet-v2에서 bottleneck architecture을 소개했습니다. 이러한 차원축소는 1x1 convolution을 통해서 할 수 있다. 1x1 convolution의 채널의 수만 조정해 더 작은 차원으로 축소 후 원하는 convolution 연산을 수행하고나서 다시 1x1 convolution의 채널 수를 조정해 원래 차원으로 복원하게 된다면 채널의 수가 줄어들었다 복원되는 >< 모양의 bottleneck architecture을 설계할 수 있다. 이렇게 하면 layer의 수는 많아지지만 같은 convolution연산을 수행했을 떄 필요햔 연산량은 줄어들게 됩니다.
댓글남기기